My name is Amir Yazdanbakhsh. I joined Google Research as a Research Scientist in 2019, following a one year AI residency. I am the co-founder and co-lead of the Machine Learning for Computer Architecture team. We leverage the recent machine learning methods and advancements to innovate and design better hardware accelerators. The work of our team has been covered by media outlets including WIRED, ZDNet, AnalyticsInsight, InfoQ.
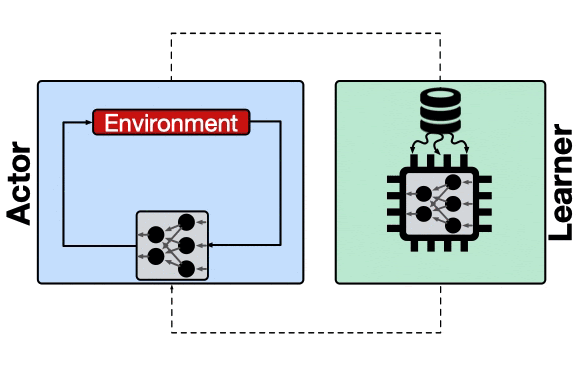
I am also interested in designing large-scale distributed systems for training machine learning applications. To that end, I led the development of a massively large-scale distributed reinforcement learning system that scales to TPU Pod and efficiently manages thousands of actors to solve complex, real-world tasks. As a case study, our team demonstrates how using this highly scalable system enables reinforcement learning to accomplish chip placement in ~an hour instead of days or weeks by human effort.
I received my Ph.D. degree in computer science from the Georgia Institute of Technology. My Ph.D. work has been recognized by various awards, including Microsoft PhD Fellowship and Qualcomm Innovation Fellowship.